
The Narrowing Path
A very brief introduction to language and models and prompting
Let's start with two intuitions about language. The first intuition is that language offers infinite possibility. Or in other words, that language is infinitely generative.
Consider for example the following sentence: "clouds compete in a sky-pattern fashion show". This sentence is completely novel and has never been said or written ever before in the history of the universe, at least as far as I know. And just in case you think that this was a particularly hard trick to pull off, I can prove that it's actually really easy by generating, on the fly, yet another completely novel sentence. How about "Eleanor said that clouds compete in a sky-pattern fashion show".
Putting one word after another it is possible to create an infinite number of new sentences. That's just a feature of language we accept for granted - it is generative.
The second intuition is that language is rather strictly constrained.
Consider, for example, a game of "guess the missing word" with the following sentence: "I was hungry, so I ate a _____". It is quickly obvious to all of us that the missing word could be "banana" or "toast" or "salad", but not "motorcycle" or "decision" or "lovely". There is a limited set of words that would work, and many others - most words, actually - that simply won't.
So language is both infinitely generative but also strictly constrained - these two intuitions are both clearly true but they seem contradictory. Can they be reconciled?
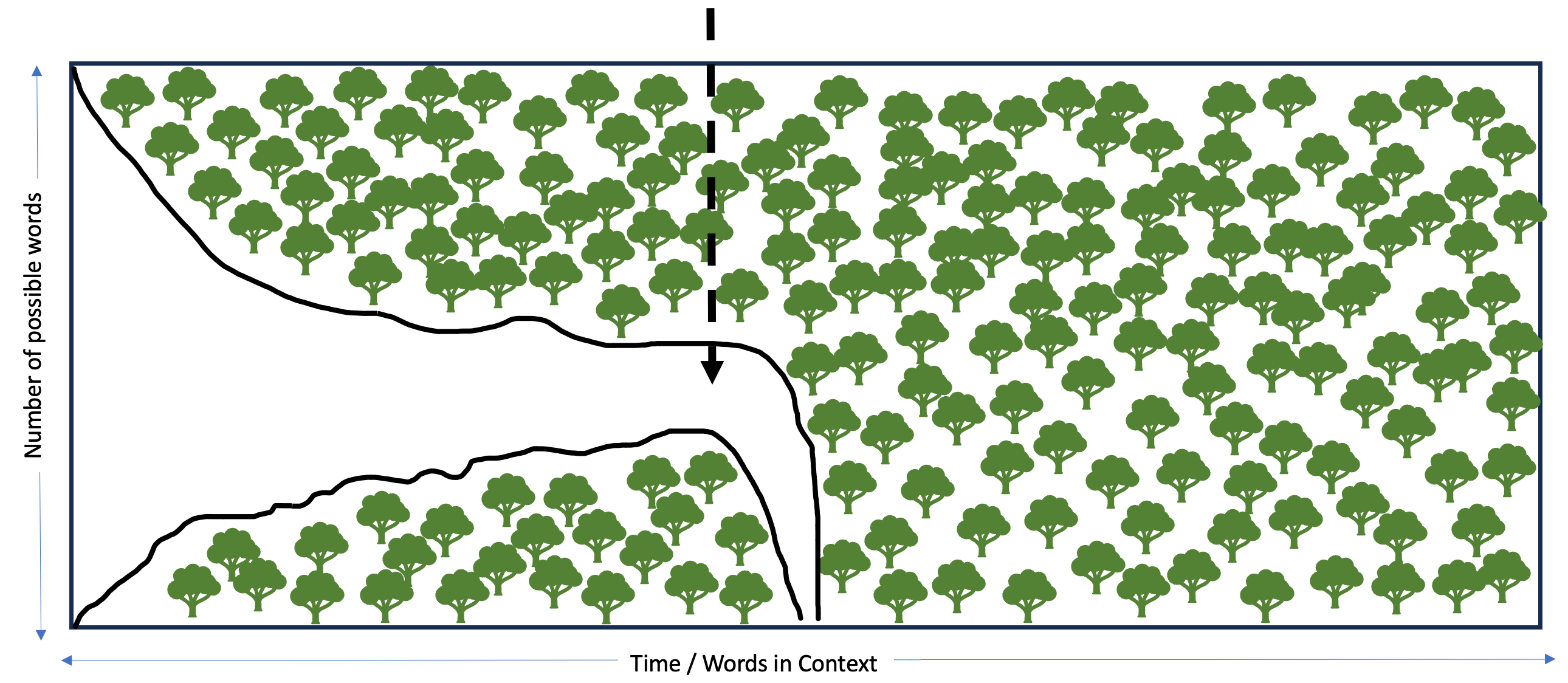
They can. The reason both these intuitions about language are true is that language is infinitely generative at the outset, but is strictly constrained in context. The context is all the words that have already been said or written. In the following graphic, the Y-axis represents the number of words available to us and the X-axis is the passage of time and the accumulation of more words in the context.

Language in context is like a narrowing path. Starting with infinite possibilities, with every new word our choices are more constrained and pointing us in a more specific direction.
These two features of language are fundamental to language modelling. Language models, like the GPT models that power Microsoft Copilot and ChatGPT, are generative devices that are constrained by context. They are trained by playing many trillions of rounds of "guess the missing word"1 and eventually learn to find a fitting word intelligently. Like us, they "know" that people eat bananas and and toasts but not motorcycles or decisions. We call that kind of intelligence "artificial intelligence".
To work with language models, we start by supplying them with context - some language, for example the question you type into ChatGPT, that will serve to constrain the model when it generates an answer. We then run multiple consecutive rounds of "guess the next word" where each new word is added to the context2 to create that narrowing path that directs the next generated word, and so on. Simple process, magical results.
Prompting, or prompt engineering, I hope you can now see, is a lot less mysterious than you might have been led to believe. What we do when we prompt a language model is use language to create a context that will constrain and direct it in a such a way that successive rounds of "guess the next word" result in a useful response.

One thing that should now be obvious, and is indeed the #1 tip for prompting, is that to exercise more precise control you should use more words. Each new word added to the context constrains and directs the language model as it generates a response.
"Hallucination", I'm sure you all know, is the received term for the phenomenon where a language model is producing a response that is grammatical, and perhaps plausible, but factually incorrect. I don't like this term because it suggests malfunction, even though what's happening is not different from any other interaction with a language model.
Like a wanderer in the woods taking a wrong turn early in the hike, getting on the wrong path, and moving further away from the destination with every additional step, a hallucinating language model generates, at some point, a word that, while not itself problematic, makes it more likely that the following words will veer ever further away from the result we hoped for. The context is constrained, just with the wrong constraints. A slightly different choice early on would have resulted in a different context that would have been more likely to generate the response we wanted.
So this is, very briefly, everything you need to know about language and about language models. As you go on to using Copilot or ChatGPT, or one of the generative APIs, remember that what you're actually doing is you use language to define a context, and thus the constraints and direction, for a fairly simple generative process.
You can get a "feel" for it and learn how to do that better with practice. But as long as you keep in mind these intuitions on how language and language models work, you have everything you need for navigating the narrowing path of language in context.
If you know a bit more about language models you’ll know that they don’t actually use words, but rather tokens, which is a different unit. We’re trying to keep things simple here, and that’s an implementation detail. If you think about it, humans also work not just with words but with smaller units like syllables and morphemes.
That too is very simplified and deviates somewhat from the actual implementation. But not in principle.